Chapter 2
We have some basic understanding of neural networks and reinforcement learning, now we need to sort out the non-machine learning stuff. First off, even if out bot knew how to play an FPS game, how would it? Making a physical robot to press buttons on a keyboard is obviously not a viable option.
What we need is an environment where my bot can play with direct access to the game’s controls. Thankfully, people have considered this problem before and built environments for some of the more popular game. OpenAI has a wonderful environment to train and test bots called OpenAI Gym. It covers a lot of Atari games and most importantly, for our purpose, Doom. Since the FPS genre started with Doom, I may as well start with Doom too. If you want to learn more about the OpenAI gym environment, please refer to the below research paper.
About OpenAI Gym
There’s also been some research on bots that can play Quake 3, another game that absolutely defined the genre. Find out more here. These environments are open source and thus the best place for me to start as compared to writing my own code to run on top of the game for my bot to access the controls and receive rewards.
Chapter 3
Thanks to the environments, all I need is a program that can make decisions on which action to play given some video input. These actions are typically indexed by numbers, for example, 0 might be to press the W key and move forward and so on. Of course, analysing video feed is no simple task for a computer, in fact, until recently this component of the project alone was considered worthy of international awards. For this task, we must make use of a convolutional neural network to process the images (video feed is just images played at several frames per second). Since we’ll be working with multiple games, our architecture must be ready to accommodate multiple convolutional nets that perform image segmentation and recognition, one for each game to be precise.
We’ll also need an LSTM layer or some other recurrent architecture to accommodate time delayed rewards from the system. Now, if you’re wondering what that means, take a look at this paper on Asynchronous Methods for Deep Reinforcement Learning by Volodymyr Mnih (2016)
So, our plan of action is build an deep reinforcement learning system that receives as input the positions of various items of interest in the scene as a vector and outputs the Q values for each action. We then select an action either based on a softmax or an adaptive epsilon greedy strategy. We have a separate convolutional neural network for each game so it’s easier to tag items that look different in different games.
Chapter 4
When it comes to programming, there’s no better way to learn that by just trying things out so now that we have a fair idea of how to approach this task, we should start writing some code to model the outlined architecture. First, let’s install the necessary tools and libraries needed for the task, starting with an environment. Since I’m working with Python on the Windows platform, I’ll install Anaconda for Windows and create a virtual environment to act as a container for the project. To create a virtual environment, use the command conda create -n venv pip python=3.6 where venv is the name of your environment.
The libraries we need include numpy, scikitlearn, pandas, tensorflow (running on the GPU preferably), keras and opencv. To save you the trouble, I created a requirements file that you can download and install using the command pip install -r trequirements.txt
Numpy, scikitlearn and pandas are mostly for manipulating desirable datatypes like numpy arrays and dataframes while Tensorflow and Keras can be used to build the neural networks we require. OpenCV will help us process images efficiently.
Chapter 5
Finally got assigned a computer at the CS lab in Mong Man Wai Building which is great because I can officially start development in a dedicated space. Of course, I’d have to reinstall all the software and libraries onto my new system. I decided to install Ubuntu, a popular Linux distribution on this PC so I could test my code on multiple platforms. Let’s just hope this doesn’t come back to bite me in back. So, I got to work flashing the OS, connecting to the new network and installing the dependencies on my new machine. Most of the process remains the same as detailed above, however, since I’m working on Linux, I can create virtual environments from the command line and Python comes preinstalled, so I didn’t have to install Anaconda.
For some further research, I also read the following papers and recommend strongly that you do the same.
Playing FPS Games With Deep Reinforcement Learning
Playing Atari With Deep Reinforcement Learning
Chapter 6
Doing a comprehensive literature review in order to prepare properly for my interim presentation next week. I read the following research papers on the application of reinforcement learning in games with special emphasis the ones that used the ViZDoom engine which I plan on using.
Training Agent For First-Person Shooter Game Wit Actor-Critic Curriculum Learning
Arnold: An Autonomous Agent to play FPS Games
Learning To Act By Predicting The Future
Deep Successor Reinforcement Learning
Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
Towards Using First-Person Shooter Computer Games as an Artificial Intelligence Testbed
A Hybrid Fuzzy ANN System for Agent Adaptation in a First Person Shooter
Yeah, I actually read all of them. Took me almost two days to completely wrap my head around some of the concepts detailed in each paper but it was definetly worth it for now I feel much more confident approaching this project.
Chapter 7
I started to tinker with the ViZDoom engine on Linux, just to get a feel of the environment. I started off simple with a script that just loaded the environment and played by selecting a random action at every step. Below is a screenshot of the clip.
I also had my presentation due on Friday the 19th so I worked on writing my report and my presentation. Preparing the presentation and report helped me reflect on my progress thus far and bolstered my ability to plan my work for the weeks to come.
Chapter 8
I installed PyTorch to test some reinforcement learning examples implemented with dynamic graphs and finally began training a simple RL model to play the basic scenario. The basic scenario is just a single room with a single enemy. The simple RL model is just a 4 layer neural network with 2 convolutional layers and 2 fully connected layers. I decided to write the first implementation of this network in Python3 with Tensorflow. It accepts a 30*45 grayscale image and can perform 3 actions, MOVE_LEFT, MOVE_RIGHT and FIRE. The model uses Q-Learning and implements it similarly to Google DeepMind's DQN (but not nearly as complicated). I assume that you know how Q-Learning works. If you don't I recommend watching AI lectures by Dan Klein and Pieter Abbeel (preferably taking the whole course).
Chapter 9
After writing the scripts to train and test my model, as well as working out kinks with the display to record videos of the training process, I finally came up with a model that performed incredibly well on the basic scenario. Below are videos of the model playing the basic scenario of ZDoom before and after 20 epochs of training.
As is fairly evident by the above videos, the performance of the model increased drastically from epoch 1 to epoch 20.
Chapter 10
After gaining some ground in Doom, I decided to shift my focus to Quake. My mind was set on making the same model work in a similar simple scenario of Quake. That would pretty much service as proof my initial idea to use the same model to play multiple shooters. In the current model, I just have 4 layers (as mentioned previously) the first two do the visual work being convolutional layers and the fully connected layers focus on the decision making with Q-Learning. I’m using the RMS loss function to introduce some non-linearities in the learning process. If the exact same architecture works on a simple Quake scenario, it would just be a matter of separating the visual cortex of each net for each game. To test it out, I had to download DeepMind Lab. I learnt more about the Quake environment and DeepMind Lab by reading this paper published by DeepMind.
Chapter 11
This week I added two convoluted layers (with max pooling) and one fully connected layer and let it have a go at the defend the centre scenario in Doom. After achieving less than ideal results, I increased the number of epochs and decreased the learning rate, giving the program more time to learn and adapt to the delta movements involved in this new situation. Below is the result of two days of training and tuning. It averaged 9 kills over it’s 10 best episodes.
Chapter 12
For fun, I played some defend the centre myself and had my friend play a few rounds too, just to get a better idea of what kind of progress I’d made (and to have some results to share during my presentation). I averaged 13 kills over 10 episodes, peaking at 16 kills in my best round and my friend averaged 9. Not looking too bad for the bot then, considering that I’ve been playing this and other games like it almost all my life.
I also fixed the issues I was having with Deepmind Lab but the basic scenario for the laser tag game in Quake Arena doesn’t seem to be as straightforward as the basic scenario of VizDoom. I also need to rewrite the final softmax to pick an action correctly in new environment.
Chapter 13
Week 13 was a busy week so I chose to focus my attention on the presentation and final report rather than the code. As any good software developer will tell you, never cram features in at the last minute. My final report can be found here and includes details on the methodology of my study and implementation of the programs so far.
Chapter 14
DeepMind Lab is officially off the table now that I’ve spent my entire Christmas vacation tinkering with it to no end. The platform as currently hosted on GitHub simply has too many bugs for the Windows and Linux platforms.
Of course, I have to replace one game with another so I did some more research on which game would be appropriate and after mulling over the choice between Wolfenstein 3D and Counter Strike 1.6, I’ve decided to go with Counter Strike 1.6 for now. Since we don’t have readymade platform built for training agents, we’re going to have to improvise. Next week, I’m going to try capturing my screen in full screen mode and look to process the video.
Chapter 15
Just as planned, I’ve written some scripts to capture my screen and to press different keys. You can find the script to capture your desktop screen in real time at about 20 fps here and a script to press the required keys to play CS1.6 here.
The first logical step is to ensure this works with a simple script that presses random keys to make sure the actions are selected appropriately. After this, we should build up the solution reach the same level as the current Doom agent by first using a simple DQN and then a more complicated version.
Chapter 16
Below is a video of the CS1.6 agent before training. This week, I’m going to let the basic DQN train on some different maps, including aim_headshot which you can get here and mini_dust which you can download here.
Coming back to Doom for a while, it’s clear that this basic architecture we’ve implemented thus far is alright for the defend_the_center, defend_the_line and basic scenarios but it’s definitely not robust enough to play at the level I want it to, at the deathmatch level. So, we’re going to have to improve the architecture of the model itself. After reviewing some notes I took while writing chapter 6 (see above), I decided to go with a combination of the architectures described in “Training Agent For First-Person Shooter Game With Actor-Critic Curriculum Learning” and “Learning To Act By Predicting The Future” (again, see chapter 6).
Chapter 17
This was quite a productive week. Below is a simple sketch of the architecture I went with for the system as a whole.
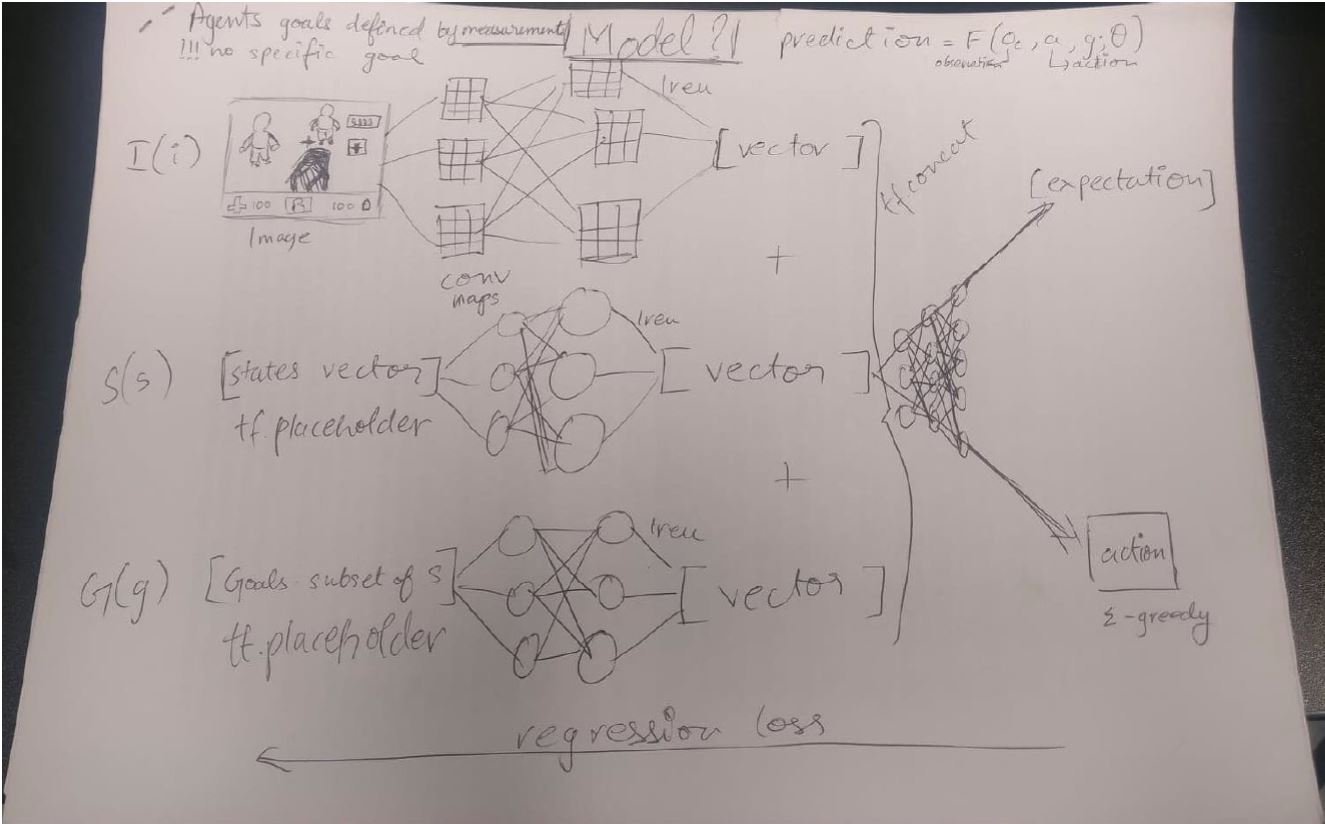
Quickly summarizing, we have 3 separate networks, one convolutional for the input images, be it in Doom or CS1.6 (Doom for now) and two fully connected layers for the measurements and goals. This permits a system of dynamic goals which is especially important because it’s the basis of the logic we humans play with. For example, if you notice your health is low, your goal shifts from just getting kills to increasing your health by collecting health packs. Thus, our priorities shift over time and an agent that is only trying to optimize one goal will never succeed as we want it to in such a complex environment.
I’m writing all the code for the network with Tensorflow (despite the models shown in the papers being tested in PyTorch) because I feel confident with Tensorflow after working with it on a few other projects.
Chapter 18
I spent this week mostly preparing for and delivering my interim presentation. I think the presentation went okay but my supervisors definitely wanted to see the agent and try the interactive multiplayer I promised them instead of just videos of it. So that’s certainly going to be my focus for the coming weeks, to perfect the model and the interactive multiplayer.
Chapter 19
I’m finally done building the main model architecture. I’ve isolated it and its various helper functions into a single file and class so as to keep the structure modular and easy to use. Here’s the file, just to explain some of it in greater detail, I use the tf.concat function to concatenate the outputs of the different networks, the conv2d function creates a convolutional neural network based on the method parameters and the fc_net function does the same for fully connected layers.
The reason I’ve opted with this structure rather than just creates the nets in the agent class is so I don’t have to re-write the code to create the multiple different fully connected networks I intend to create (projects generally just use one network so there’s no need to create a function for this). The lrelu function implements the leaky relu activation function required for introducing some non-linearities. The code is commented profusely so you should be able to understand the rest by going through it.
Chapter 20
I’ve started work on the interactive multiplayer and it seems to be working okay. The central idea is to make it work with on just one computer on the PC’s localhost. This will remove all the hassle of LAN and having to install all the libraries and moving files from one computer to another, having to connect the computers etc.
To achieve this, we need to host a game on the local host and allow the user to control the player on the host using one script, then open another terminal and run a different script that connects to the localhost but runs the agent’s main function to choose actions.
I achieved the above set up quite easily using VizDoom’s host argument in game arguments while creating the VizDoom instance. I’m also planning on exploring multiprocessing for this task so I don’t have to start up two terminals and run two scripts every time I want to test the multiple player. I could also automate it with a batch file. I’ll upload both of those once I’m done.
Chapter 21 & 22
This was a very busy couple for weeks for me personally, so I wasn’t able to get a lot done. I began the long training process which took two nights. Finally, I had the weights ready in a neat 220-megabyte file (sarcasm).
I tested it out a lot on different scenarios using the two-script setup I developed last week and it seemed to work really well. Much better than expected actually. It averaged about four kills a game against me while I managed nine. Not bad, considering I’ve been playing this game for quite some time now. It also seemed quite robust in the sense that it wasn’t repeatedly doing the same things and (thankfully) wasn’t mindlessly running into walls. Here is a video of it playing against me. I’m going to retrain it with some different parameters because I think this can be even better.
Chapter 23
This week brought with it a successful implementation of the multiplayer with multiprocessing! I wrote a script that leverages the Process library in python to spawn one process and run the main method of agent instructing it to join a game hosted on the localhost (127.0.0.1) and the main process hosts and runs a spectator instance of the game allowing the user to play. The bot and player will thus be spawned into the same map and attempt to kill each other in a classic deathmatch scenario.
Taking it one step further, heres a script that spawns as many versions as the agent as specified in a command line argument and allows the host to play against them all at once. Be careful not to burn out your CPU though, each instance of the agent you add is an extra process.
Chapter 24
Very busy week with every course’s final project due but I managed to link the model to the CS1.6 convolutional network and test it against the easy bots on aim_headshot. Unfortunately, the multiplayer for CS1.6 is not going to be as straightforward due to the lack of a platform meant for learning.
Since we’re simply grabbing the screen buffer images and processing the video stream from there, we obviously can’t run a bot on the same computer as the host (because the bot has to see the view of the character it controls and the player has to be able to see his character’s view). Thus, I have to make this work over LAN or the Internet but I don’t think I have enough time to do this right away so I’m going to have to leave this for later.
Chapter 25 & 26
I spend most of my time refactoring and documenting my code this week. I also began on writing the report and preparing for the presentation. I had to do three separate presentations, the final internal presentation to just my advisors, a fast track presentation to encourage students to attend my presentation and a public final presentation. I also had to make a video for the fast track video, I’m not the best when it comes to making videos but here’s what I managed. Here is the final fast track video.